Kesako Bibliosurf
Bibliosurf : Veille littéraire interactive et indépendante depuis 2015
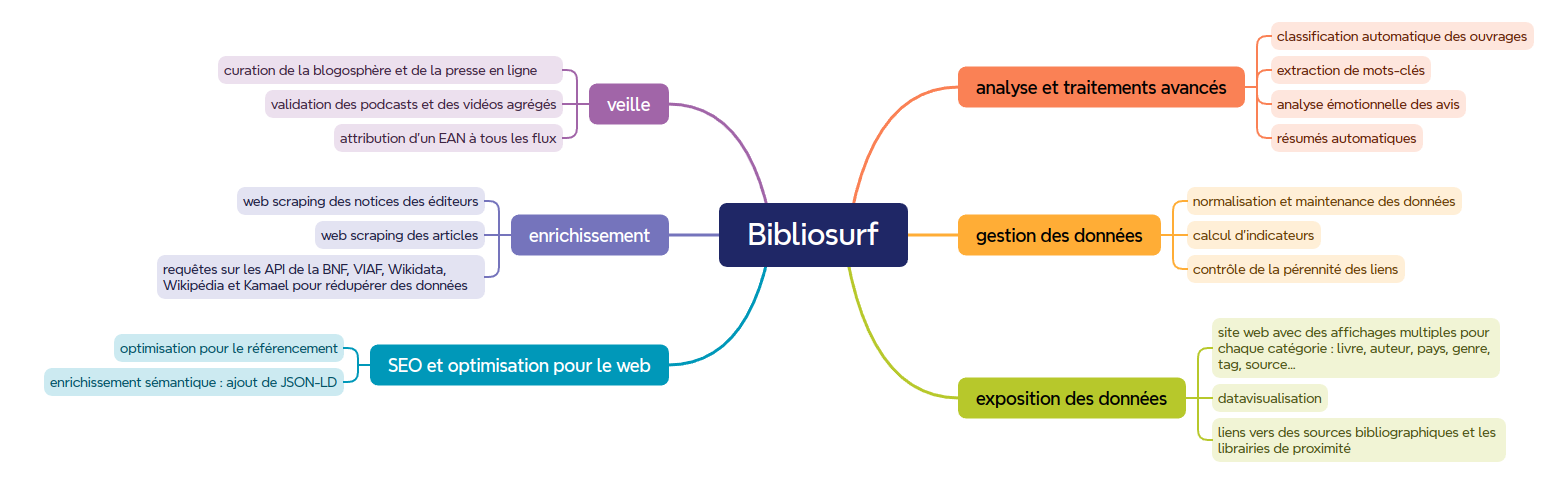
Depuis septembre 2015, Bibliosurf surveille l’actualité du web littéraire.
Chaque jour, il scrute la presse en ligne, les blogs, les podcasts et les vidéos pour offrir un panorama complet des discussions littéraires.
Cette veille repose sur plusieurs méthodes : agrégation de flux RSS, alertes Google, exploitation de données issues d’API, comme Youtube.
Les métadonnées sont enrichies via les API de Wikipedia, Wikidata, la BNF, idref et VIAF.
Pour structurer l’ensemble, Bibliosurf indexe les pages référencées à la manière d’un moteur de recherche.
Enfin, des modèles de langage avancé permettent de générer automatiquement des résumés, des FAQ et des réponses à des questions diverses.
Bibliosurf est aujourd’hui l’un des rares projets francophones à croiser veille littéraire, intelligence artificielle et navigation enrichie, dans une démarche totalement indépendante.
Conçu et animé chaque jour par Bernard Strainchamps, Bibliosurf est sans publicité, propose des liens sans affiliation et ne revend aucune donnée.
Ce que Bibliosurf vous propose :
– Une veille littéraire quotidienne, multimédia et indépendante
– Des outils interactifs d’analyse et de visualisation
– Des liens vers les ressources de référence (BNF, Wikipedia, VIAF, Worldcat) et vers des librairies indépendantes
Identifiants Bibliosurf :
Chaque livre et chaque auteur sur Bibliosurf dispose d’un identifiant pérenne, indépendant de l’URL lisible.
– Exemple pour un livre : https://www.bibliosurf.com/id-livre-135504
– Exemple pour un auteur : https://www.bibliosurf.com/id-auteur-25484
Ces URI stables permettent de référencer de manière unique les notices Bibliosurf dans Wikidata, VIAF, ISNI ou d’autres bases, même si les adresses web lisibles venaient à évoluer.
L’URL lisible reste l’adresse principale pour la navigation et le référencement (par exemple https://www.bibliosurf.com/Titre-du-livre.html).
Architecture technique
Bibliosurf repose sur une architecture technique éprouvée, associant le CMS SPIP, l’agrégateur Feedly et des modèles avancés de traitement du langage (SpaCy, MoussaKam/barthez, GPT-4o). L’analyse des données est enrichie par des outils interactifs comme OpenStreetMap, Chart.js, dataTable, VIS et jQCloud.
Vie privée
L'hébergeur OVH dépose un cookie technique qui sert à surveiller l'état du serveur.
Bibliosurf utilise le script Matomo hébergé en local pour les statistiques.
Demande de consentement : la page booktubes intègre les cookies de Youtube qui ne sont pas sous le contrôle de Bibliosurf.
Pour des raisons éthiques, Bibliosurf n'est plus présent sur les réseaux sociaux.